So, in the first post of this issue, I wrote about what problems and issues I had and what I was seeking to solve them.
As I told before a co-worker told me that Gitlab has some extended features and then he introduced me to the Gitlab API.
Then I started my quest of developing a LV Code to interact with this API.
Git API
It turns out that most of the majors hosting git repositories/platforms have a REST API, in that includes Gitlab, Github, Azure Devops, Bitbucket, AWS Code Commit.
If you have no idea what is a REST API, I suggest you by start reading this link.
Just summing up, it is a model (architectural style) that most of the web uses for synchronous requests protocols, exchanging information between a client and server.
LabVIEW itself has an API for dealing with such HTTP Requests. JKI also developed over this API a toolkit for simplifying the requests and responses, which are very tricky to deal with.
So, to have an idea of the scalability of this solution, any public Git repository of any language could be used as a dependency. I mean, if it is private and you have access then it also can be used.
What is a tag?
The mandatory recommendation is to have a tag versioning system compatible, in this case, Semantic Versioning.
A tag is a point referenced to a commit in your source code control system. So it is not your commit per se, it is a fancy name for it, instead of using the long commit hash, you use i.e. “v1.0.0”.
Most of the developers already use tagging and something very close to semantic versioning, so changing it is not a challenge, and different from the code itself, you can change tags and apply retroactively, although most of the time it is not a good idea, it can be done.
Dependencies and Project Organization
After studying for a while the API, doing some tests with LabVIEW and command-line interface (using curl), I came up with a rudimentary version (quick and dirty of the code). This was, of course, the test version.
I realized that a problem would have to be solved first: the cross-linking in LabVIEW. For example: if your library depends on the other library, and that library depends on a third library. But your main library depends also on the third library. What a mess, isn’t it? This diagram will help you understand better.
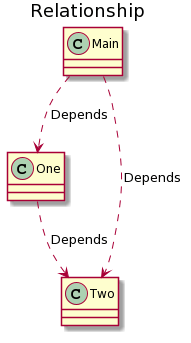
The main code downloads a dep1 (One) and dep2 (Two). The dep1 also downloads dep2. So now we have two dep2 in two folders, one within the main library and another within the dep1 folder.
The point is: to solve this, I came up with a solution that turned out to be a good choice for standardizing projects hierarchy in our company (future post on it).
My solution was to put all the files that I want in a folder called “libraries”, so the dependencies would be always in parallel folders relative to each other, and that solved my issues with libraries depending on each other, code duplication and cross-linking.
Implementation
After playing around with Gitlab API, I came up with the second solution on that first one (can I call it quicker and dirtier?). It has the following features:
- Read all the projects in the Gitlab;
- Retrieve all tags
- Allows user to select tags;
- Generates a JSON file with these tags;
- Check for JSON file in the selected tags;
- Download the source code into libraries folder;
- Put dependencies libraries into read only mode.
- Insert dependencies in .gitignore to not be uploaded to SCC;
I thought that a video would be self-explanatory, so I recorded a small video executing the process.
Version 2
When I decided to write post I had also put the second version in a planning step. Quicker and Dirtier became a headache, many bugs and not handling correctly errors. But for this, I thought that at first, it would be good to raise the Requirements, “Pros” and “Cons” of the viable solution that would require minimum effort, based on the current solution.
Pros
- Use an already settled infrastructure (Git Hosting Plataforms);
- Easy to understand;
- Needs only tags and a json file in the main project;
- There is a command line for quick downloading;
- Any project can be used as dependencies (python, c++ libraries, etc…);
- NXG Compatible (not the app itself, but the downloading);
- It checks for updates;
- Written in G;
Cons
- Not fully developed and tested yet;
- To use it, folder structure refactoring in the projects is needed;
- Written in G, so, run-time engine needed (not that bad, after all it will be used by LV developers);
- Does not handle LV Version issues;
- Do not handle completely dependency versioning. Although it downloads only one of each, it does not guarantee that the versions will be inter-compatible.
Looking at these points, it really got me motivated to continue this project, but I thought the requirements could go further. If people embrace this idea, it could be possible to turn this project open-source. Here are some required features (and risks) to allow everyone else to use it.
Desired Features and Risks
- Allow any Git platform API – Maybe doing some class inheritance/interface to change between different providers. The APIs are different, although required functions exist in most of them;
- Extend command line, not to only download, but do some extra configuration;
- Extend JSON configuration files, to include other information such as licence, authors, contributors, copyrights, LabVIEW Version;
- Include automatically libraries in the lvproj (VI Server). A plus, not really necessary.
- Allow reading/downloading assets in Releases Page for people who use Packed Libraries (lvlibp).
- It would rather have a local cache to avoid too much downloading and increase speed in setting up big projects;
- Show projects Readme and Changelog.
- It would depend on someone else’s repository (you could prevent yourself by removing those files from .gitignore and uploading to your SCC)
Verdict
Well, this solution, for now, is really useful for me. I can move between my projects without worrying about dependencies. I really see the possibility of expanding this project, imagining that you would just need any repository link to list tags and include in your project.
But, it is just a thought of a community project, if it has enough feedback, we may keep talking and advancing on this agenda.
Would you use it?
What features are missing?
Let me know what you think in the comments below.

I have a question. Maybe this is answered above but I just missed it.Can you elaborate a little more on how this differs from submodules? What exactly were you trying to accomplish that submodules don’t do? and more to the point, why would I as a developer choose this implementation over using submodules, or any of the other solutions for that matter?
In some ways it seems like you are mixing VIPM and submodules. It seems like the json file appears to do something similar to a vipc file in that it captures the various versions installed (of course a vipc can also contain the code.) and then you can version that with your code. Getting the source code by downloading it from a git repo feels like submodules.
Can you elaborate more? Just trying to understand it all and how it fits in. That’s a lot of questions so perhaps another post?
LikeLiked by 1 person
Hi Sam. Yep, maybe this will be forwarded to another post.
One issue I found was the cross-linking using submodules
You have one submodule (1) that depends on other sub-module (2). That’s an ok situation. Then you have a super project that has these two submodules. When this last one loads its submodules, the submodule (1) will load itself the submodule (2). That’s ok if you have only one depending on submodule (2). Then you have submodule (3) that depends on submodule (2) and downloads it. Then we have a submodule (2) inside submodule (1) and submodule (2) inside submodule (3). For LabVIEW is a problem it will force you to use only one, and to save the files, or else, you always get that “Warning Dialog”.
Second, it is easy to use, just a file. If you want to change, just change that file and commit it. With submodules will have to run update then commit, then push, and all the process.
Also, you may use across any “gitlab” installation, I am not entirely sure, but submodules are not allowed to use with another repository instead of your own.
Like you said, it is something between VIPM and submodules (with the possibility of downloading just one folder inside the remote repo).
LikeLike
Hi Felipe,
I think this seems pretty nice. As you’ve described here, I also found putting dependencies in a shared folder in parallel (I’m now using PPLs two years on) to be a good way to avoid ugly linking problems. This took a bit of work for the build system but is now straightforward for me (similar I think to how you’ve built your own dependency management system and now it’s straightforward for you).
I have some Python code that uses requests to publish releases to my GitHub repositories – if that would be useful to you let me know. I suspect it can be ported to LabVIEW directly if desired (and I might do that when I get time anyway – I’m considering trying to put everything directly inside a LabVIEW process but have to consider if I want to handle multiple LabVIEW versions – my current process in principle allows this but running the build system in a LabVIEW process would make that a bit more difficult I expect).
Thank you for writing these interesting posts and I look forward to reading some more (if you write more!)
LikeLike
Hi Christian,
As I’ve read too, the best way is to keep all dependencies in parallel folders, something that is not possible to achieve completely with submodules.
The Python code may be interesting somewhere in the future as I evolve the application, for now, I will try to leave the application more usable and only with the basic features. On the other hand, I am very interested in PPLs, mainly because I found very difficult to manage them with AF. =/
As I mentioned in the first post, I evolved into this solution because I saw your presentation, therefore I should say thanks. Always feel free to leave your comments and let’s keep talking.
LikeLike